












If you want to know why we have Snowflake in the first place, check out this blog by our previous Data Engineer!
When it comes to Data, we are mostly charged for two things: Storage and Processing. Snowflake, which is where our data warehouse lives, has a tool for admins that shows the summary of these costs for the month so far, as well as for the previous six months. This tool is the best place to start when it comes to finding out what’s going on in your warehouse.
When comparing the information gathered by this tool for Mixmax, two things became clear:
- Storage had been growing steadily, adding around a terabyte a month, for the last six months, and
- Processing had been growing exponentially (twice as much in the last eight months), and something weird had definitely happened in November and December (three times as much processing costs as in October).
In this blog, we’ll go over how we handled storage optimization. There are many ways on which we can optimize processing, and we actually applied quite a few. Check out our previous post to find out what we did!
Optimizing Storage
The storage costs were a shock to me since I’d previously been working with the allegedly biggest tables in our model, which didn’t even get to a single terabyte. So, the question arose: Where is all that storage? Do we have that many tables?
What’s Going On??
By diving into the Storage tab for the tables (also available in Snowflake for Admins but easily calculated from information_schema on the DB) and sorting by size descending, it became clear that we had two VERY large tables.
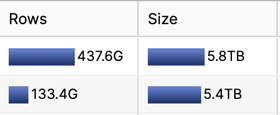
These two tables represented 60% of the current storage, and were about 110 times bigger than the biggest business table. Also, the query that fed one of these tables was flagged as the #5 most expensive query.
Taking a closer look at the monthly detail, these two tables collectively grew a bit more than a terabyte each month, and then each month even a bit more. When asking my fellow Mixmax engineers about the content of these logging events, we realized that they were hardly ever used. They were required as an audit and in case really old debugging was needed, but since they’d started keeping them in the DWH they were only queried twice.
What Do We Do Now?
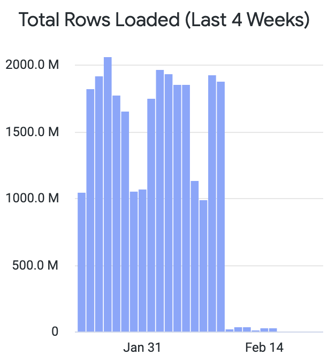
After looking into alternatives, we decided to move this information into AWS Glacier for a year and re-import it into the DWH if needed. AWS Glacier costs were about 3 times cheaper at the time than Snowflake’s active Storage, and since we were getting no value from that raw information, we were gaining nothing. That said, this was clearly a bet and it could’ve gone horribly wrong. Be cautious if tempted to follow our steps. We were confident that we were not going to recurrently need to use this information, since the import cost in that scenario would’ve ended up being higher than the storage cost optimizations.
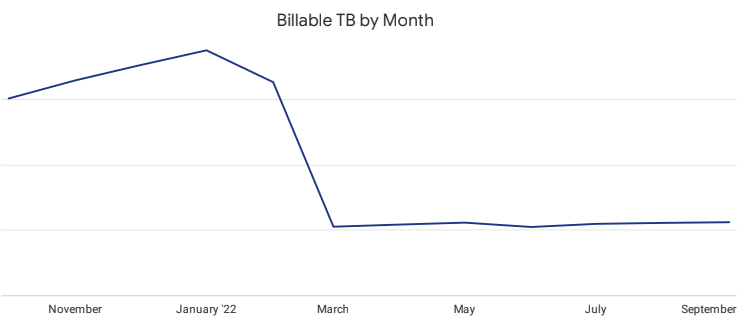
Removing this information implied a cost reduction of $10K this year! And since storage without a cleanup policy (which we didn’t have) is cumulative, we were talking about an extra $50K worth of 3 years of storage.
Almost a year after that decision was made (and fingers crossed), we haven’t had the need to go into that information again. I can gladly confirm that we’ve been paying a fifth of what we would’ve paid having kept those logs in the DWH.
Anything Else We Can Do?
For other sources that actually brought insights to the business and allowed us to better understand some features’ performance, we made some tweaks on how we’re keeping that information. Instead of complete snapshots through and through, we’re keeping the raw info as a whole only for the features that had modifications. This allows us to be able to recreate history accurately, and reduce the amount of redundant information. Redundancy is a good thing, sometimes.
Additionally, analyzing Table #4 in the storage ranking helped us realize we had a bug when saving automated notifications that didn’t expire from the original MongoDB collection, as they were supposed to. After the cleanup, we ended up keeping only 1% of useful feature-related information.
Keep in Mind!
There is not one right answer that fits all our problems. What seems right today may not be right in a few months or years.
We need to be smart on how and when we apply the Data Principles. We need to contextualize, balance pros and cons, probably compromise in one way or another, and not set our ways in stone: if what we did is not working as expected, try again! If you think you can do better, go for it! If you don’t know what to do: ask for help!
Want to solve data problems? Visit Mixmax Careers.

