












Salesforce integration is an important part of our business here at Mixmax, so we always want to make it better and improve performance. In this post, I’ll share more about one of our latest iterations of Salesforce integration.
But First, A Little Context
At Mixmax, we often have code that can be used across projects but relies on a shared group of resources, constants, rules, or other items. When this happens, we commonly encapsulate these resources into a single package and distribute it via npm to be used in different projects as needed.
For our original Salesforce integration, we used the same method and it worked perfectly. We were able to consolidate all of the integration domain into a single package and expose an API for its logic to be executed by the pertinent consumers.
But fast-forward several years and Mixmax has grown a lot, and our integration has grown along with us. With this growth, maintaining a single colossal package to contain all of the integration domain was starting to become a burden. Our API borders for the package had become blurred, and changes often required almost day-long update cycles to roll them out to all of the importers. The list of annoyances, confusing patterns, and time-sucking requirements was long, and we knew we needed to change. And because we value speed and consistency in our development at Mixmax, we also knew that it was time to get out of the shadow of our integration colossus (quick PS2 break, anyone?).
Our approach to regain our speed and consistency was to consolidate our integration into a monorepo, where we could distribute the domain of the integration into smaller libs with clear APIs and tests. Other libs and microservices of the monorepo would take leverage from these and together construct a collective domain. From a single source of truth, we could deploy our microservices, consumers, and external npm packages, with no more unclear APIs or package bumping. (Spoiler: The result was absolutely gorgeous.)
Splitting the Colossus
We began planning out our approach. The codebase was huge, so we needed to break it into smaller pieces to take action. In order to keep the effort healthy and avoid downtimes or regressions, we split our migration into three acts. With each individual act we would learn new tricks to better nail the next one, and we would also create checkpoints in the migration process.
The First Act: Migrating Repositories
In our first act, we migrated our package as-is from the original repository to the inside of our monorepo. In this act, we learned how to nail the intricacies of the CI and CD pipeline for a package, so that the consumers of the package didn't notice any difference and we as engineers could start to see the benefits from the migration. In the process, we also learned how to creatively compare code-diffs to make sure we would not be messing with the APIs in place.
A beautiful changelog
The Second Act: Smaller Libs
With the lessons learned from our first checkpoint behind us, we started to break the integration down into smaller libs. Each of the smaller libs was to be responsible for one context of the integration and have its own set of tests and exports. Keeping consistency in mind, we took the approach of having a single aggregator whose responsibility was to import all of the smaller context libs and export a package with the exact same API as before. With this approach, the code that lived inside of the monorepo could start to take advantage of the breakdown, while external importers of the package could continue to have their businesses running.
The end result was pretty good, and Nx, the library we use to organize our monorepo, gifted us this gorgeous dependency graph:
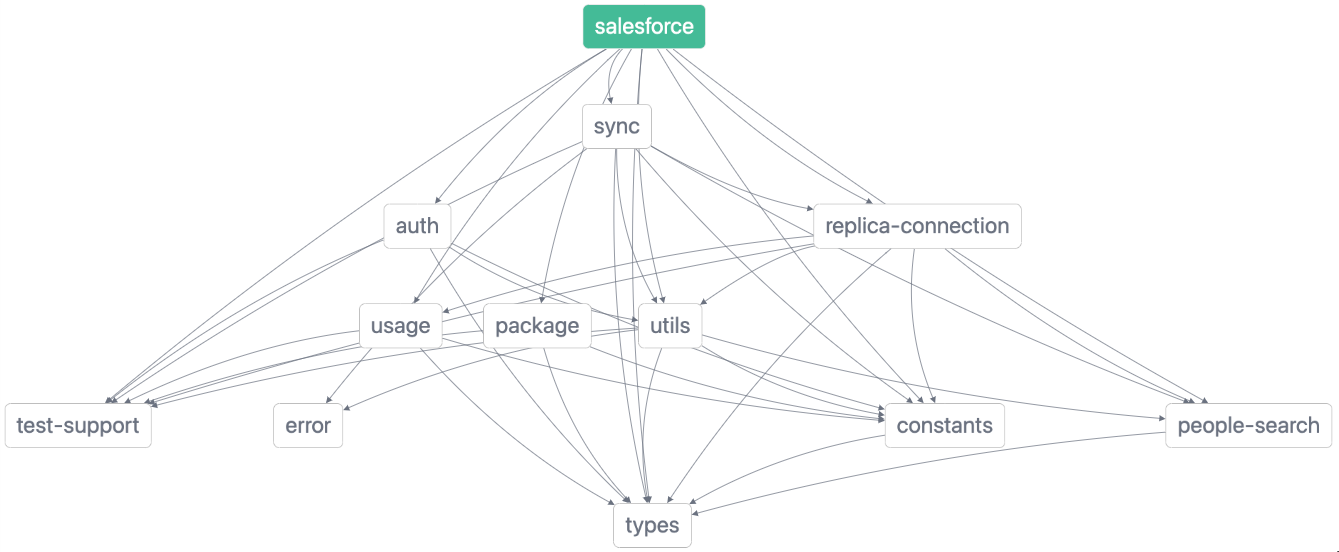
The Third Act: Concise Boundaries
For the last act in our migration, we needed to update and refactor our libs to express concise boundaries and expose solid APIs, so that the importers of the lib could have a clear understanding of a library’s input/output notion about it. We are still working on this today. The effort will probably yield a new post one day with the lessons learned. And this time, no spoilers!
In The End
In our constant pursuit of excellence, we learned a lot about how to structure and split code when it gets way too big for its shell. As for me, I'm excited with the results and for what we'll gain from these improvements, like getting faster with our development cycles while enhancing code readability and governance, and creating a solid foundation for growth. But this is just the start for our integration refactor and monorepo. Stay tuned for the next episode.
Hey, let's build this together. If you're interested in building future-proof, rock-solid integrations like these (and much more cool things), check out our open positions! :)

